How to protect your creative work from AI training


Think about the last time you shared a photo on Instagram. Now imagine that same photo being used to train AI models without your consent. One moment you're showcasing your latest picture, and the next, it’s part of a vast dataset feeding algorithms. For professional artists, this use of their work presents even greater quandaries.
The rise of AI has sparked incredible advancements, but it comes with a cost. Creatives around the world are finding their work repurposed, often without their knowledge or approval. And the issue extends beyond privacy—it's about ownership, consent, and the ethics of using human creativity to teach machines.
Join us as we explore the complexities of this digital dilemma. We’ll unravel the methods AI companies use to train their models, spotlight the challenges of opting out, and offer practical steps to protect your creative work from becoming just another data point. Lauren Hendry Parsons, Director of Communications & Advocacy at ExpressVPN, will also weigh in on the implications of AI training on people’s privacy and what it means for our digital future.
How AI trains with user-generated content: 5 steps
AI training is a complex process that involves using extensive amounts of data to teach machine learning models how to recognize patterns, make decisions, and generate content. Essentially, every piece of content you share online can potentially become a small part of this vast learning process.
Here's how it works:
- Data collection: AI companies gather massive amounts of data from the internet. This includes everything from public social media posts to images and videos.
- Data labeling: Once collected, this data needs to be labeled. For instance, an image of a cat needs to be tagged as “cat” so the AI can learn to recognize it.
- Training the model: The labeled data is fed into the AI model. The model processes the data, learning to identify patterns and make predictions based on the information it has received.
- Fine-tuning: This step involves refining the AI model’s capabilities, ensuring it can accurately understand and generate content. This might involve additional rounds of training with more specific data sets.
- Deployment: Finally, the trained AI model is deployed, ready to perform tasks like generating art, writing text, or even moderating content.
AI training: Copyright and ownership concerns
While the process of data collection by AI companies might seem harmless at first glance, the reality is far more complex and contentious. Companies often gather data from a variety of public online sources, including social media posts, images, and videos, to train their AI models. But how are these companies allowed to access and use this content for AI training?
The answer lies in the terms and conditions of the platforms where users share their content. Most social media platforms and online services have terms of service agreements that grant them broad rights to use, modify, and share user-generated content. When you sign up for these platforms, you might unknowingly consent to these terms, which can include allowing third parties, like AI companies, to access and use your data.
Not surprisingly, this extensive use of user-generated data for AI training has given rise to significant copyright and ownership issues. These concerns were first thrust into the spotlight with the emergence of AI-generated art. AI models like DALL-E and Midjourney can produce striking original artwork by learning from vast datasets of existing art. However, the originality of these creations is debatable, especially when these models are trained on copyrighted works without the artists’ permission.
Artists argue that this practice infringes on their intellectual property rights. Using their work to train AI models, which then create similar art, can undermine the value of their original creations. This issue has thrust the debate over ownership and creative rights into the spotlight, highlighting the ethical dilemmas posed by AI training.
Meta’s AI training controversy
While the debate over AI training and copyright concerns continues, a recent controversy involving Meta, the parent company of Instagram, Facebook, and Threads, has brought these issues to the forefront. The tech giant has recently come under scrutiny for its plans to use content from its platforms to train AI models, starting on June 26, 2024. This practice has sparked significant backlash, particularly because of the difficulty users face when attempting to opt-out.
In the European Union (EU), the General Data Protection Regulation (GDPR) provides a way for users to opt-out. However, Meta has made this process unnecessarily complex. Notifications sent to users feature prominent “close” buttons, while the actual opt-out links are hidden in tiny, hard-to-see text.
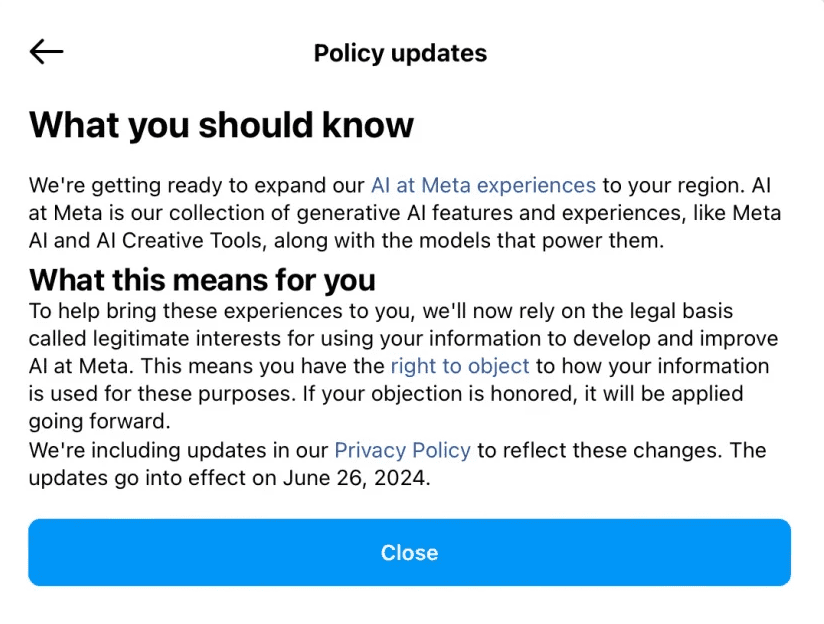
Even if users manage to find the correct link, they are met with cumbersome forms requiring personal information and explanations for opting out, adding layers of effort and discouragement.
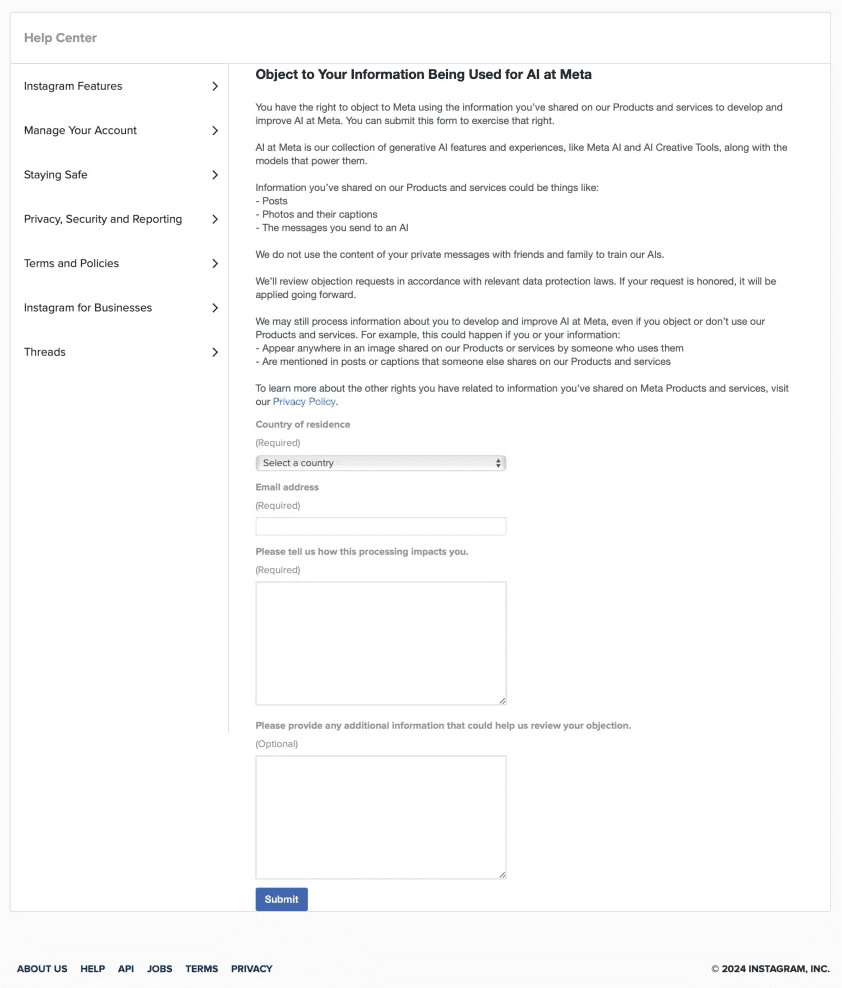
In other parts of the globe, the situation is even more challenging. If users aren’t based in the EU, they’ll have limited options to opt out of their data being used for AI training. While Meta allows some opt-out methods for third-party data usage, these are often not well-publicized.
Despite Meta's claims of complying with local laws and asserting that AI training is essential for developing inclusive features, the backlash highlights a broader issue: the lack of transparency and the difficulty in exercising user rights.
Adobe’s questionable terms of service update
In addition to Meta’s AI training controversy, Adobe recently faced similar backlash over recent updates to its Terms of Service. The uproar began when Adobe users misinterpreted the new language, fearing that their unpublished work could be used to train Adobe's AI models, including its Firefly AI.
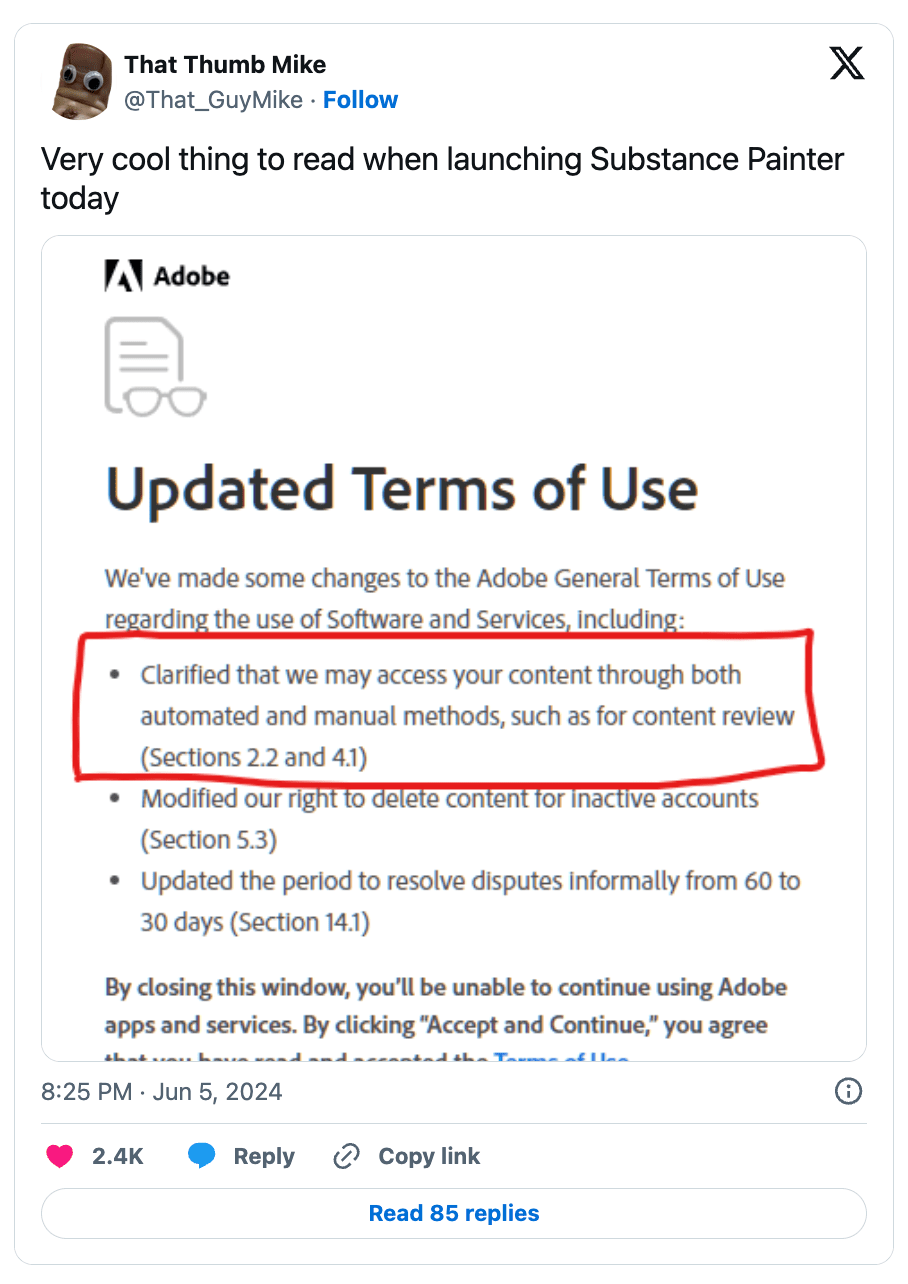
The confusion arose from a sentence in Section 2.2 of the updated Terms of Service, which states: “Our automated systems may analyze your Content and Creative Cloud Customer Fonts...using techniques such as machine learning to improve our Services and Software and the user experience.” This vague wording led users to believe that their private and unpublished works were at risk of being used for AI training.
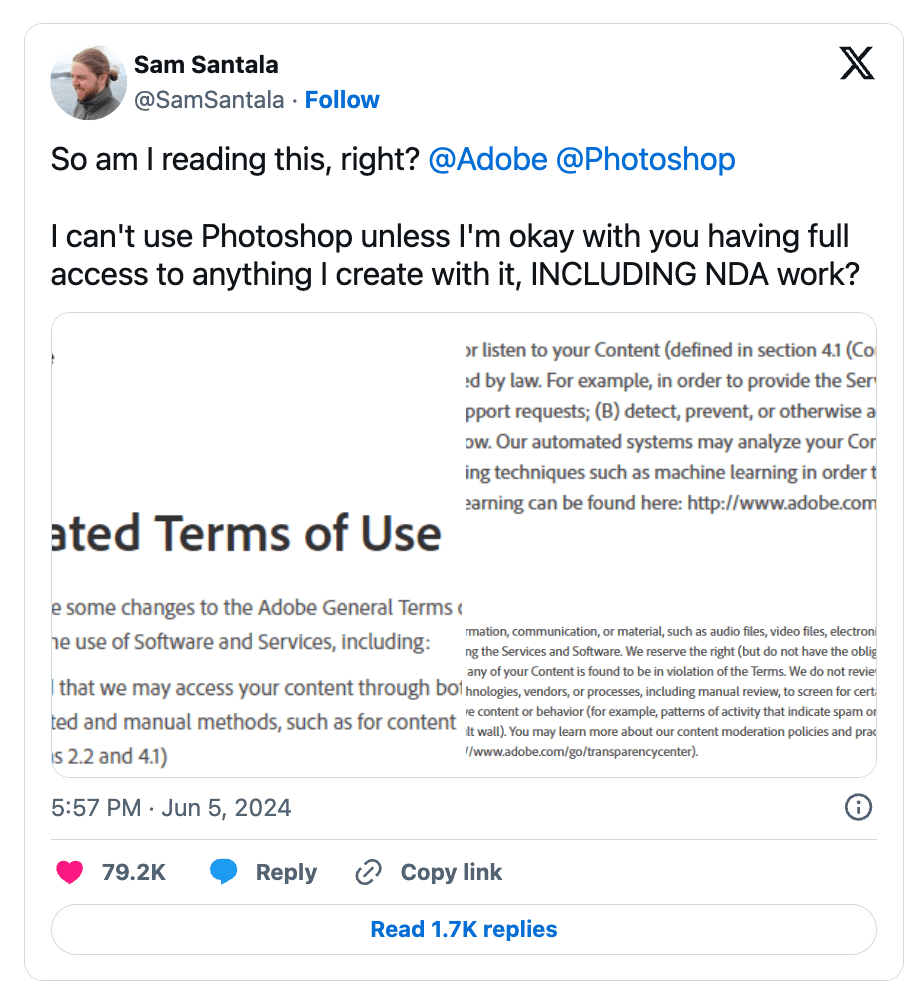
Adobe addressed the concerns in a blog post, explaining that this part of the policy was not new and primarily pertains to moderating illegal content and preventing the creation of spam or phishing attempts. The company assured users that their AI models are not trained on personal, unpublished content. However, despite these reassurances, the initial ambiguity in the update caused widespread fear and mistrust among Adobe’s creative community.
The dark side of AI training
The issues surrounding AI training can also take a darker turn. One possibility is the inclusion of images of children—inadvertent or not—in datasets. For example, in early June, Human Rights Watch reported that over 170 images and personal details of children from Brazil were included in an open-source dataset (which comprises billions of images) without their knowledge or consent. These images, some dating back as far as the mid-1990s, were taken from personal blogs, maternity sites, and low-view YouTube videos.
LAION, the organization behind the dataset, has since taken steps to remove the flagged images following the report. However, the situation raises significant concerns because children can't give informed consent, and the use of their images for AI training disregards their autonomy and privacy. Globally, the legal framework to protect children's images in AI training is often insufficient, leaving them vulnerable to severe risks, including AI-generated child sexual abuse material (CSAM) and deepfake exploitation.
And children aren't the only vulnerable population at risk. Marginalized communities, such as racial minorities and low-wage workers, are also disproportionately affected. AI systems often reflect societal biases present in their training data, which could potentially lead to discriminatory practices in hiring, lending, and law enforcement.
Another concerning issue is the use of non-consensual explicit content, such as revenge porn, in AI training datasets. This form of digital abuse can severely impact victims' emotional and psychological well-being. The unauthorized inclusion of such content in training datasets perpetuates its circulation and misuse, posing significant challenges for protecting individuals' privacy and dignity.
“Social media platforms, creation apps, and other digital spaces are places where content creators expect a level of control and ownership,” explains Hendry Parsons. “The repurposing of these images for AI training raises severe ethical and legal concerns. From complex opt-out processes to ambiguous policy updates, and now the potential exploitation of vulnerable populations, it's clear that oversight and regulation in AI training practices are urgently needed.
“We need stricter data protection laws and better enforcement to protect everyone, especially vulnerable groups. People deserve to know their data won't be used without their consent, and companies must be transparent about their practices.”
Understanding your legal rights and options
Given the complex and often opaque world of AI and data usage, understanding your legal protections is more important than ever. As AI continues to evolve, knowing your rights can help you safeguard your creative work and personal data from being misused.
Europe’s GDPR
The GDPR stands as one of the most stringent data protection laws globally, designed to put control back into the hands of EU citizens. If you live in Europe, here’s how it safeguards your data:
- Data access and control: Under Article 15 of the GDPR, you can request access to your personal data held by an organization. This means you can find out what data is being collected, how it's being used, and who it's being shared with. This is particularly relevant for AI training, as it allows you to understand if and how your data is being used to train AI models.
- Right to erasure: Also known as the “right to be forgotten,” this allows you to request the deletion of your personal data under certain circumstances, such as when it's no longer necessary for the purposes it was collected for, or if you withdraw your consent. This means that If you discover your data is being used for AI training without your consent, you can request its deletion.
- Consent: GDPR mandates that organizations must obtain clear and informed consent before processing your data. This ensures that you are aware of and agree to the use of your data, which must be given freely without any coercion. Companies using your data for AI training must have your explicit permission.
- Transparency: Companies are required to be upfront about their data processing activities, including AI training, providing clear and accessible information about how they use your data.
Understanding ‘legitimate interests’
A key concept in GDPR is “legitimate interests,” which allows companies to process your data without explicit consent if they can justify that their interests do not override your rights and freedoms. For AI training, this means that companies might use your data without direct consent if they believe their use case is justified. Here’s what this entails:
- Balancing test: Companies must conduct a balancing test to weigh their interests against your rights and freedoms. This test assesses whether the benefits of processing data for AI training outweigh the potential impact on your privacy.
- Transparency and accountability: Even under legitimate interests, companies are required to be transparent about their data processing activities. This means they should inform you about how your data is being used, why it’s necessary, and what safeguards are in place to protect your privacy.
- Right to object: You have the right to object to the processing of your data under legitimate interests. If you object, the company must stop processing your data unless they can demonstrate compelling legitimate grounds that override your interests, rights, and freedoms.
Outside the EU, data protection laws are less uniform. In the U.S., for instance, data privacy is regulated by a combination of federal and state laws, which can be less comprehensive than the GDPR. However, they do provide some related protections.
California Consumer Privacy Act (CCPA)
The CCPA is one of the strongest state-level privacy laws in the U.S. If you’re a California resident, it provides several significant protections:
- Transparency and access: You have the right to know what personal data is being collected and for what purpose. You can request access to this data, similar to GDPR's provisions. This right helps you understand if your data is being used for AI training.
- Deletion rights: You can request the deletion of your personal data, giving you more control over what information companies retain. If your data is used in AI training without your consent, you can request its removal.
- Opt-out of sales: The CCPA allows you to opt-out of having your data sold to third parties, enhancing your control over how your data is used. This is particularly relevant if data brokers are supplying your data for AI training.
- Anti-discrimination: Companies are prohibited from discriminating against you for exercising your CCPA rights, ensuring that you can freely protect your privacy without facing negative consequences.
However, the CCPA doesn't go as far as the GDPR in some areas, such as the right to correct inaccurate data. The concept of legitimate interests also doesn’t have a direct equivalent in federal data protection laws.
Additionally, other states like Virginia, Colorado, and Utah have enacted their own data privacy laws, but these often provide narrower protections compared to the GDPR and CCPA. This is why it’s essential to be aware of the specific laws in your state and how they protect your data.
8 ways to protect your creative work
Understanding your legal rights is an important foundation, but it’s only the first step. To truly safeguard your creative work from unauthorized AI training, you need to take proactive, practical steps. Here’s how you can fortify your digital presence:
1. Use platforms with transparent policies
When selecting platforms, go for those that clearly spell out their data usage policies and offer simple opt-out options. Always read the fine print to grasp how your data might be utilized. Choose platforms that provide regular updates about their data policies and ensure they maintain transparency.
2. Review and adjust your privacy settings
Regularly audit the privacy settings on your social media platforms. This means diving into the settings menus to see who can view and interact with your content. Social media giants like Facebook, Instagram, and X offer detailed guides to help you adjust these settings. By limiting the exposure of your content to unintended audiences, you significantly reduce the risk of it being used without your consent.
3. Opt-out where possible
Get familiar with the opt-out processes available on various platforms. Some platforms allow you to opt out of data sharing with third parties, which can help protect your data from being used in AI training. Additionally, consider using services that help you opt out from data brokers who might sell your information to AI companies. This extra step can help you retain control over where your data goes.
4. Be cautious about sharing content
Think twice about what you share publicly. Utilize privacy settings to restrict access to your content, sharing only with trusted individuals. For particularly sensitive or valuable content, use private groups or encrypted messaging services. Watermark your images or use low-resolution versions to deter unauthorized use—watermarking not only asserts your ownership but also makes your work less appealing for misuse.
5. Use metadata and copyright notices
Embed metadata and copyright notices directly into your digital files. This can include your name, the date, and usage rights information. Metadata serves as an extra layer of protection, clearly asserting your ownership over the content and making it easier to track and prove authorship if needed.
6. Monitor and track your content
Use tools and services designed to monitor the web for unauthorized use of your content. Services like Google Alerts, Pixsy, and TinEye can help you track where your images or other digital works appear online. Regular monitoring allows you to quickly address any unauthorized use and take appropriate action.
7. Encrypt sensitive content
For highly sensitive work, consider using encryption tools to protect your files. Encryption adds an extra layer of security, ensuring that only those with the decryption key can access your content. This is particularly important for work that could be highly valuable or damaging if misused.
8. Use legal tools and reporting mechanisms
If you’re in the EU, leverage the GDPR to file complaints against companies that misuse your data. The GDPR provides a formal mechanism for addressing data privacy violations, offering you a way to hold companies accountable. In the U.S., report violations to the Federal Trade Commission (FTC).
The future of AI and creative work
The rise of AI has brought significant advancements but also substantial challenges, particularly for creators whose work may be used without consent. Looking ahead, the relationship between AI and creative work will become even more complex, presenting both new opportunities and ongoing ethical dilemmas.
Ongoing developments in AI
AI continues to evolve at an unprecedented pace. From generating hyper-realistic images and videos to composing music and writing prose, the capabilities of AI models are expanding rapidly. For creators, this means new tools that can enhance their work, streamline their processes, and unlock new creative potential. However, these advancements come with a significant caveat: the need for transparency and consent in how AI is trained.
“The potential of AI in creative industries is enormous, but it's essential that we strike a balance,” says Hendry Parsons. “Creators should have control over how their work is used, and their consent should be a fundamental requirement in the AI training process.”
The need for stronger regulations and ethical standards
As it stands, the regulatory framework around AI training is fragmented and inconsistent, leaving many creators vulnerable to unauthorized use of their work. Comprehensive legislation that addresses the complexities of AI training, consent, and ownership is an important step forward.
Hendry Parsons emphasizes, “We need stronger regulations that prioritize the rights of creators. This includes clear guidelines on data usage, consent, and transparency. It's not just about protecting individual rights, but also about fostering an ethical AI ecosystem that respects human creativity.”
Moreover, the development of ethical standards in AI is equally important. These standards should be guided by principles of fairness, accountability, and transparency. “By adhering to these principles, AI companies can build trust with creators and the broader public, ensuring that technological progress doesn’t come at the expense of ethical integrity,” adds Hendry Parsons.
“Awareness is the first step toward empowerment. Creators must stay vigilant and advocate for their rights. By coming together and demanding transparency and ethical conduct from AI companies, we can shape a future where innovation and creativity coexist harmoniously.”
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN